So, like I’ve already mentioned in my previous comment, I’ve got some free time to work on my pet project here.
Development progress
I’ve been optimizing a lot under the hood. Tons of blood, sweat and tears have already run into optimizing the core parts.
Coming from a different background in programming, namely a desktop background, doing embedded development is a whole new experience for me. And let me say this: it’s definitely a refreshing one.
Development for embedded devices can be quite challenging if you have hard memory limitations and performance restrictions CPU-wise. These limitations go even further than the ones I’m used to when doing component or graphics development. And I’m doing quite a lot of that…
Just so you get the idea:
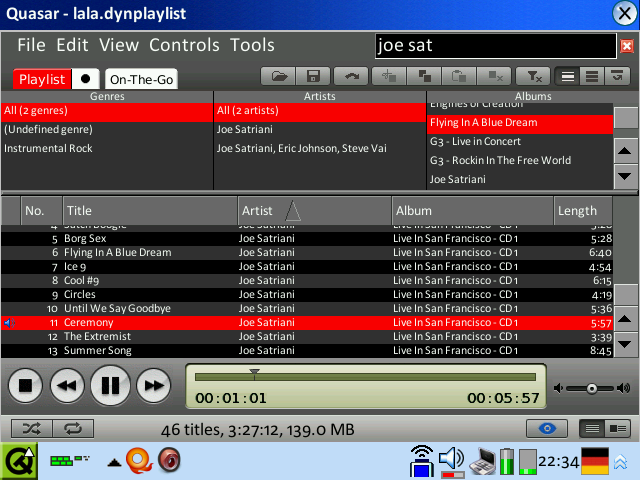
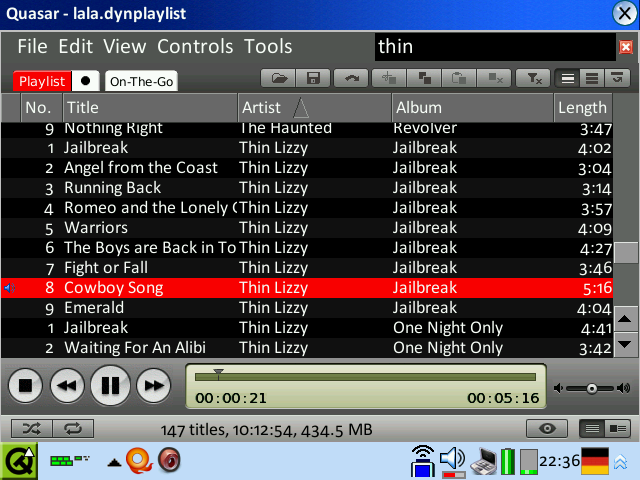
My essential requirement for this project is that the player is able to cope with thousands of files in a playlist.
With that being said, I’ve already rewritten the playlist management four times. :)
The first approach was fast but ate RAM for breakfast. Incremental searching on a playlist was fast but also required additional memory. The second approach was more memory-friendly, but searching was slow. Besides, some Qt widgets make development a real pain – at least in Qt/E 2.3.x. For instance, QListView can pose an incredible hog on performance. I’m currently using several hacks to speed things up. However, I’m still thinking about replacing the whole component or doing some custom coding to improve it…
Anyway, since I couldn’t really get rid of the memory problems, I finally decided to give SQLite a try. SQLite offers very sophisticated caching, which helps getting rid of the RAM problem. I really could use the enhanced features of a SQL database. And let me say this: SQLite is awesome. And it’s as fast as it could be on such a small device – that is, if you know how to use it…
With that being said, different rules in database design apply for embedded systems:
In the third approach I already created a pretty decent database schema. Something I naturally would have done on a desktop system. Keeping the layout clean, using relations where applicable, minimizing data storage requirements.
On a desktop system dereferencing and joining tables is fast. However, not so on my Zaurus: Simple left-joins over three tables would take up to a few hundred milliseconds. In contrast, these queries are almost unmeasurable on my desktop system, meaning they were faster than 10 ms.
Now add a few other equally expensive queries to that and imagine, you’re doing a search on your playlist with 2000 items. Do you want to wait 3 seconds or longer for the result? That’s not what I call interactive.
So, I had a nice profiling, optimizing and testing marathon last weekend. To make a long story short, after analyzing the bottlenecks and also having a lengthy discussion with a DB-guru friend, I ended up simplifying the database schema in a direction I wouldn’t normally take on a desktop system. It’s not totally ugly now, but it’s just not as relational as you might expect a SQL database to be. Also, some data is redundantly held in temporary tables, which isn’t nice either, but helps performance A LOT.
In order to do the profiling I made some changes to the SQLite codebase, which I will post shortly along with some optimization hints. Update: Hints here, patch here.
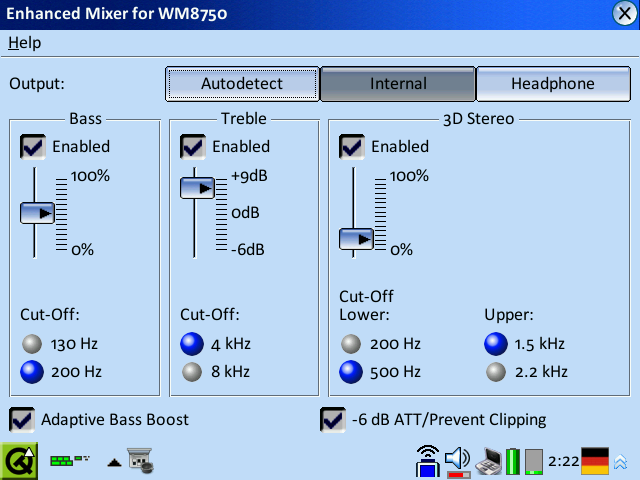
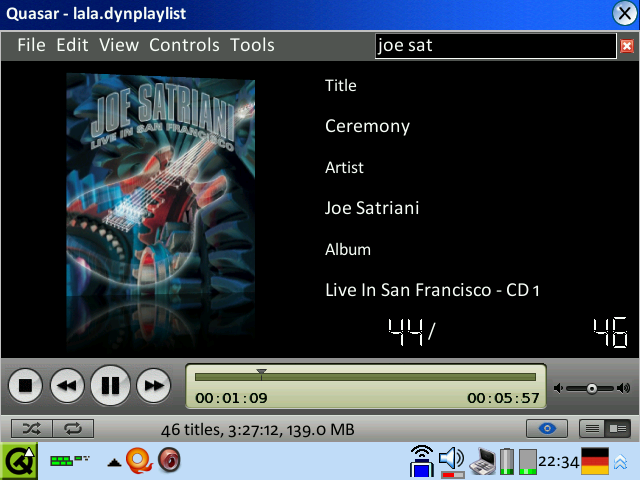
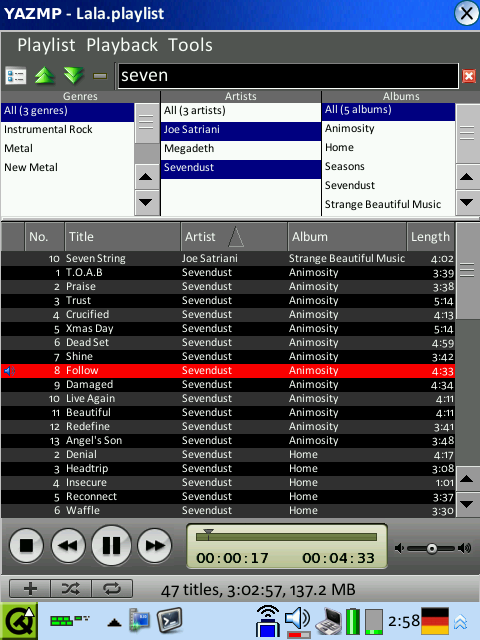
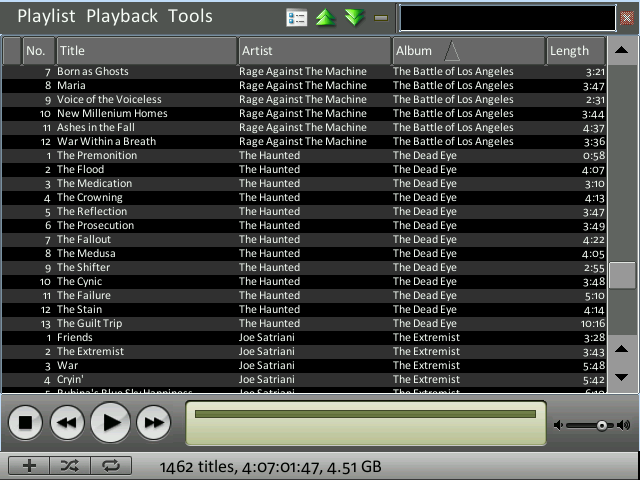
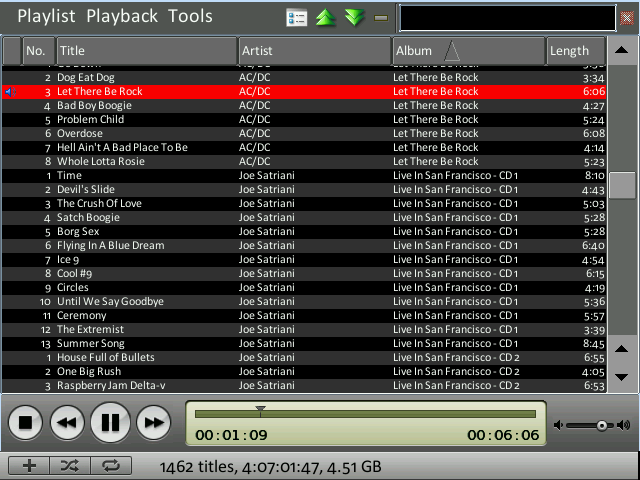
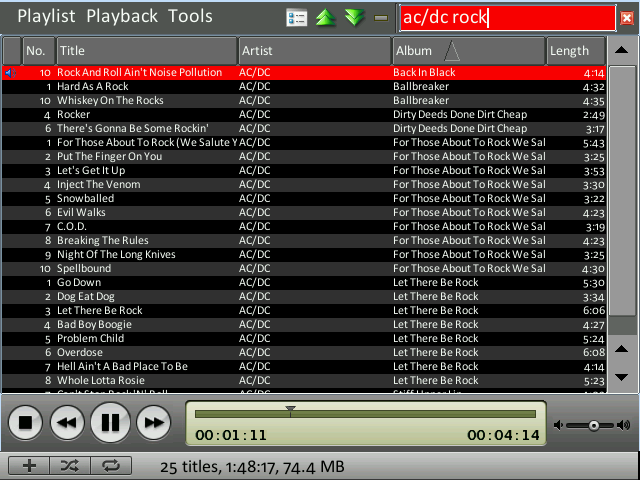
Screenshots
No release yet, sorry! I have to finalize some features first.
However, here are some new screenshots that show the new overview feature in action. The design of the application is temporary, stay tuned! :)