Encoding Types
This topic describes the types of SMS encoding.
7-bit GSM encoding
7-bit GSM encoding supports the GSM 7-bit default alphabet and GSM 7-bit default alphabet extension table through an escape mechanism.
Figure 1

Figure: Escape mechanism
The GSM 7-bit default alphabet consists of 128 characters. Each character is represented by 7 bits. 10 extra characters are defined in the GSM 7-bit default extension table. These characters are represented by an escape mechanism using the escape character (0x1B). For example, 0x1B65 maps to the Euro sign € (U+20AC). If an escape character byte is followed by a character that is not included in the 10 characters, the escape character is just ignored. This means 0x1B41 maps to Latin capital letter A (U+0041).
For more information about the GSM 7-bit default table, extension table and escape mechanism, see 3GPP TS 23.038 V8.1.0.
Lossy 7-bit encoding
Lossy 7-bit encoding enlarges the character set supported by 7-bit GSM encoding. Some Unicode Characters do not exist in the target 7-bit set. These characters are converted to ones that do exist in the target 7-bit set and closely resemble the original, intended character. A lossy encoding using a 7-bit encoding is more cost effective than a UCS-2 encoding.
Example of 7-bit encoding
Accented Latin characters are not supported by 7-bit GSM encoding. Figure 2 describes how an accented Latin characters Á, is sent by SMS. Á has a Unicode value of 0x00C1. When it is processed by the Lossy converter the character is converted from the Unicode to 7-bit code letter A. A has a 7-bit code of 0x41. The SMS receiver reads A instead of Á. By substituting the character that is similar enough to the original, the reader can understand the word. The process of converting Á to A is called a lossy conversion.
Note: The 7-bit code of A (0x41) can only be decoded back to the same Unicode letter A instead of Á.
Figure 2
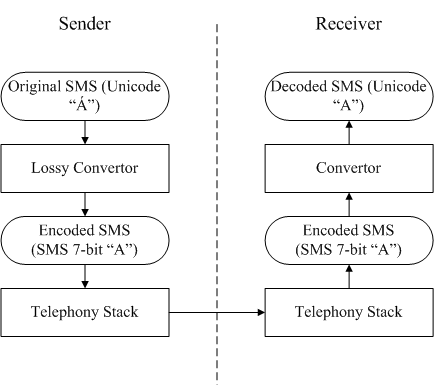
Figure: Lossy conversion
16-bit Unicode encoding
Unicode is an international standard character set. It includes the characters of every language. In Unicode, each character is usually encoded in two 8-bit bytes, and takes up more space than 7-bit encoding.
National language encoding
According to 3GPP TS 23.038 V8.1.0, National Language Encoding supports additional characters for certain languages which cannot be represented in the GSM default 7-bit alphabet. It defines two mechanisms for doing this:
Locking shift mechanism–the default GSM table is replaced with a table containing the character set needed for a language. The table is referred to as locking shift table.
Single shift mechanism–the GSM extension table is replaced with a table containing the character set needed for a language. The table is referred to as single shift table.
When the locking shift mechanism is used, the escape table can be the existing GSM extension table or it can be the escape table used by the single shift mechanism. This supports three possible mappings as shown in Figure 3:
The GSM 7-bit default escapes to language-specific escape table. It is referred to as GSM-single.
The Language-specific basic table escapes to GSM 7-bit default extension table. It is referred to as locking-GSM ext.
The Language-specific basic table escapes to language-specific extension table. It is referred to as locking-single.
Figure 3
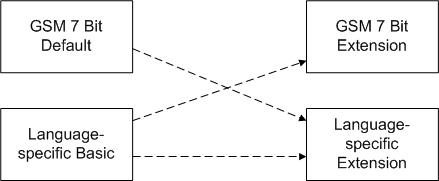
Figure: National language encoding
The single shift mechanism is useful when a message contains only a few characters outside the default GSM table. It is however inefficient when a message contains many unsupported characters, because each escaped character must occupy 2 bytes. GSM-single supports more characters than locking-GSM ext, but these characters are in the single table, which takes 2 bytes. Locking-single is used more for the decoding purpose in case the extra characters can come from the locking or single table.
The locking or single table is not a complete replacement. For example, the locking table for Turkish redefines only 8-character codes from the default GSM table, as shown in table 1. The escape table for Turkish adds 7 characters to the GSM extension, as shown in table 2.
GSM 7-Bit Code |
Turkish Locking Shift Table |
GSM 7-Bit Default Table |
|---|---|---|
|
I LATIN CAPITAL LETTER I WITH DOT ABOVE |
¡ INVERTED EXCLAMATION MARK |
|
ç LATIN SMALL LETTER C WITH CEDILLA |
¿ INVERTED QUESTION MARK |
|
€ EURO SIGN |
è LATIN SMALL LETTER E WITH GRAVE |
|
i LATIN SMALL LETTER DOTLESS |
ì LATIN SMALL LETTER I WITH GRAVE |
|
G LATIN CAPITAL LETTER G WITH BREVE |
Ø LATIN CAPITAL LETTER O WITH STROKE |
|
g LATIN SMALL LETTER G WITH BREVE |
ø LATIN SMALL LETTER O WITH STROKE |
|
S LATIN CAPITAL LETTER S WITH CEDILLA * |
Æ LATIN CAPITAL LETTER AE |
|
s LATIN SMALL LETTER S WITH CEDILLA * |
æ LATIN SMALL LETTER AE |
GSM 7-Bit Code |
Turkish Single Shift Table |
GSM 7-Bit Extension Table |
|---|---|---|
|
I LATIN CAPITAL LETTER I WITH DOT ABOVE |
|
|
ç LATIN SMALL LETTER C WITH CEDILLA |
|
|
i LATIN SMALL LETTER DOTLESS |
|
|
G LATIN CAPITAL LETTER G WITH BREVE |
|
|
g LATIN SMALL LETTER G WITH BREVE |
|
|
S LATIN CAPITAL LETTER S WITH CEDILLA * |
|
|
s LATIN SMALL LETTER S WITH CEDILLA * |
For more information about the National Language Identifier, Single or Locking mechanism, see 3GPP TS 23.038 V8.1.0: National Language Identifier.