Files Containing Multiple Content Objects
Content Access Framework provides a generic mechanism for exploring
files that contain multiple content objects. These files are often
referred to as archive files. This can be .ZIP compression archive or a DRM protected archive, such as an OMA .DCF file. An application can explore the content objects
inside a file using the ContentAccess::CContent class.
Structure of a file containing multiple content objects
An archive file can have content objects and meta-data or information associated with the content. This meta-data can include information, such as the MIME type of the content, the encryption algorithm, the compressed size of the content.
The content and meta-data may also be arranged in a hierachy with container objects grouping content objects together. A typical archive can have a complex structure as the example shown below:
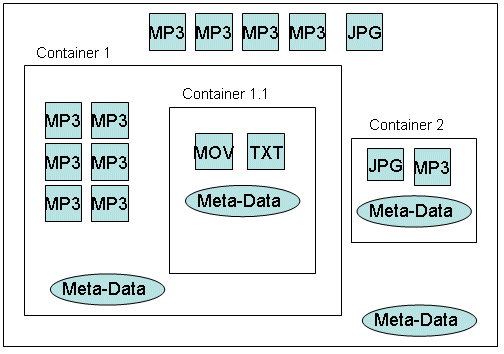
In this scenario, the file itself can be considered as the
top level container. All other content, containers and meta-data are
nested inside. In an archive file, applications can quickly search
for the content objects they are interested in by using ContentAccess::CContent::Search(), see Consumer
API Tutorial.
Identifying a content object within a file
Archive files containing several content objects cannot be referred to using just the URI of the file. The Content Access Framework uses a concept of virtual paths to identify content objects within a file. The virtual path is a combination of the file URI and a unique identifier supplied by the agent:
A content file is only handled by the agent that recognises
it. The unique identifier is not required to be decoded by anyone
other than the agent that generated it, so the format is left for
the agent to implement as it sees fit. For instance, an OMA DRM agent
may put the Content ID (CID) in the UniqueId field.
The only constraint is that the UniqueId must
be unique within the file. An application must be able to directly
reference a content object just using the UniqueId.
Objects used to identify a content object within a file
Virtual path pointer objects on the stack
The ContentAccess::TVirtualPathPtr is used to point to two descriptors holding the URI of a file and
the UniqueId of a content object within the file.
It can also be used to point to another TVirtualPathPtr. Since it is only a pointer, the original descriptors used to initalise
the TVirtualPathPtr must not be destroyed or modified
while the TVirtualPathPtr is still in use.
The ContentAccess::CVirtualPath class stores the file URI and content object UniqueId in its own descriptors. There is a cast operator that allows the CVirtualPath to be used as if it were a TVirtualPathPtr .
Examples
// Open a CContent object to browse the objects inside a file
CContent *c = CContent::NewL(_L("C:\file.dcf"));
CleanupStack::PushL(c);
// Create an array to store the embedded objects
RStreamablePtrArray<CEmbeddedObject> myArray;
// Get an array of the embedded objects within the current container in the file
c->GetEmbeddedObjects(myArray);
// If necessary we can get a "mangled" version of the URI that
// references the particular object within the file
// i.e. "C:\file.dcf\\OBJECT1"
CData* data = iContent->OpenContentL(EPlay,myArray[0]->UniqueId());
TFileName uri;
data->GetStringAttribute(EPreviewURI,uri);
.
.
.
// Now we can use our TPtrC later to create a TVirtualPath object from a URI
TVirtualPathPtr aPtr = aURI;
// print the file URI "C:\file.dcf"
printf(aPtr.URI());
// print the content object's UniqueId "OBJECT1"
printf(aPtr.UniqueId());
// Create a copy of the virtual path on the heap so we don't have any ownership problems
CVirtualPath *myVirtualpath = CVirtualPath::NewL(aPtr)
// Can now delete the CContent object without losing our VirtualPath
CleanupStack::PopAndDestroy(c); Special cases for the UniqueId field
KNullDesC16() - ""
A zero length UniqueId is used to refer
to the entire file. If a file is opened this way, no translation of
the contents is performed. The ability to open the file with no translation
is required for example to attach the file to an outgoing message.
As with any other function in CAF, access to the file is at the agent's
discretion.
KDefaultContentObject() - "DEFAULT"
Allows an application to refer to the default content object
within a file. In the case of an unprotected file handled by the F32Agent, it is the entire file, the same as if the UniqueId "" was used. Other agents, particularly
those with a single content object embedded within the file, use "DEFAULT" to refer to their only content object.
Even though the DEFAULT content object is supported,
it is recommended that agents always use CContent to enumerate the objects within the file.